728x90
반응형
SMALL
분석모형 설계
1. 분석 절차 수립
1.1 분석모형 선정
- 분석 목적과 데이터 특성을 고려해 적절한 모형 유형을 선택하는 단계
- 통계기반
- 회귀분석, 상관분석, PCA, ANOVA, 판별분석
- 인과관계/차이/요약 중심의 해석 가능 모델
- 예: 키와 체중 관계, 남녀 성적 차이
- 데이터마이닝 기반
- 분류, 예측, 군집, 연관규칙
- 패턴·트렌드 발견, 비즈니스 중심
- 예: 장바구니 분석, 고객 분류
- 머신러닝 기반
- 지도학습, 비지도학습, 준지도학습, 강화학습
- 데이터에서 스스로 학습, 성능 우선
- 예: 스팸 메일 분류, AI 강화학습
- 비정형 데이터 기반
- 텍스트 마이닝, 오피니언 마이닝, SNS 분석
- 텍스트/이미지/네트워크 등 비정형 처리
- 리뷰 감성 분석, 유튜브 댓글 분석
1.2 분석모형 정의 시 고려사항
| 고려 | 요소 설명 | 예방 전략 |
| 과대적합 (Overfitting) | 훈련 데이터에 집착하여, 새로운 데이터에 일반화되지 못함 | 교차검증(K-fold), 규제(L1/L2), Dropout |
| 과소적합 (Underfitting) | 단순한 모델이라, 데이터의 패턴을 제대로 포착하지 못함 | 모델 복잡도 증가, 더 많은 특성 활용 |
| 모형 선택의 오류 | 문제에 부적합한 알고리즘 사용 | 회귀 ↔ 분류 혼동 주의, 문제 정의부터 점검 |
| 변수 선택의 오류 | 중요 변수를 누락하거나, 불필요 변수를 포함 | 전진/후진 선택법, 상관성 분석 등 |
| 데이터 편향 | 특정 특성만 반영된 데이터로 인해 편향된 결과 생성 | 데이터 수집과 전처리 단계에서 샘플링 주의 |
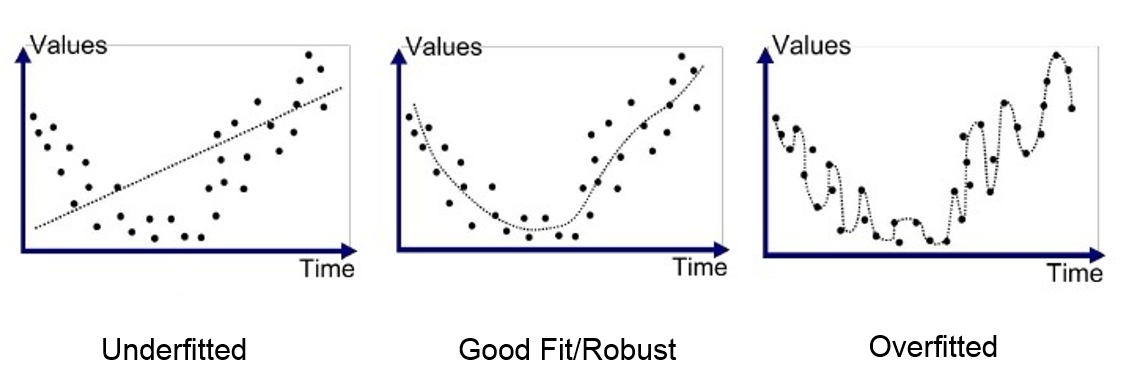
과대적합과 과소적합의 핵심 차이는
“복잡도”와 “일반화 능력”의 균형에 있음.
과대적합은 훈련 성능은 좋지만 테스트 성능이 나쁨!
2. 분석모형 구축 절차
2.1 요건 정의
- 분석 목표 설정: 비즈니스 과제를 명확히 정의 (예: 고객 이탈 예측)
- 수행 방안 설계: 사용할 데이터, 범위, 일정, 리소스 등 계획 수립
- 분석 요건 확정: 성과 지표(KPI), 정량 목표, 분석 범위 최종 확정
문제 정의가 모호하면 모델이 아무리 정확해도 쓸모없음
협업 부서와의 조율이 이 단계에서 필수
2.2 모델링
- 데이터 탐색 및 정제: 이상값, 결측치, 변수 분포 확인 및 처리
- 변수 선택/생성: 주요 예측 변수 선택, 파생 변수 생성
- 모형 설계 및 학습: 알고리즘 선택 후 학습 (ex. 회귀, 트리, 신경망)
- 성능 평가: 정확도, F1 Score, AUC 등 기준으로 평가
과대적합/과소적합 주의
K-fold 교차검증으로 일반화 성능 확인
성능 평가지표는 비즈니스 목표에 맞게 선택
2.3 검증 및 테스트
- 운영 환경 모사 메스트: 실제와 유사한 데이터로 검증 수행
- 시나리오 기반 테스트: 다양한 가정(what-if)을 통해 예외 상황 점검
- 비즈니스 효과 비교: KPI 개선율, 기대 수익 등과 연결하여 분석
기술적 성능뿐만 아니라 비즈니스적 실효성 판단 중요
기존 시스템과의 연동 가능성도 검토 필요
2.4 운영 적용
- 운영 시스템 적용: API 또는 배치 작업으로 예측 시스템 구현
- 모니터링 및 피드백: 정기적 성능 점검, 데이터 드리프트 대응
- 지속적 개선: 신규 데이터 반영 → 모델 재학습/튜닝 수행
운영 환경에서는 속도, 해석력, 안정성 모두 고려
MLOps 기반 자동화도 점차 중요
✅ 요약
| 단계 | 설명 |
| 요건정의 | 분석 목표/요건 도출 → 수행계획 수립 → 분석 요건 확정 |
| 모델링 | 데이터 탐색 및 전처리 → 변수 선택 → 모델 설계 및 구축 → 성능 평가 |
| 검증 및 테스트 | 실제 환경에서 테스트 → 비즈니스 KPI와 비교 분석 |
| 운영적용 | 운영 시스템에 적용 → 성능 모니터링 및 지속적 개선 |
📌 "기획 → 구축 → 검증 → 적용"의 4단계 사이클
3. 데이터 분할 전략
- 모델링 성능을 검증
- 과대적합/과소적합을 방지하기 위해 데이터를 여러 집합으로 나눔
3.1 데이터셋 분할 종류
| 구분 | 설명 | 목적 |
| Training Set (훈련용) | 모델을 학습시키는 데이터 | 가중치 학습, 패턴 인식 |
| Validation Set (검증용) | 하이퍼파라미터 조정용 | 과대적합 방지, 모델 튜닝, 조기종료 |
| Test Set (평가용) | 최종 모델 성능 측정 | 일반화 능력 검증 |
💡 보통 분할 비율은
→ Train:Val:Test = 6:2:2 또는 7:1.5:1.5
✅ 예시
- 고객 이탈 예측 모델 개발
- 전체 데이터 10000명
→ 7,000명: 훈련(70%)
→ 1,500명: 검증(15%)
→ 1,500명: 테스트(15%) - 모델 훈련 후, 검증 데이터로 튜닝, 테스트 데이터로 성능 최종 평가
3.2 고급 분할
| 전략 | 설명 | 활용 예시 |
| K-Fold 교차검증 | 데이터를 K개로 나눠가며 학습과 평가 반복 | 데이터가 적을 때, 검증 데이터 낭비 최소화 |
| Stratified Sampling | 분할 시 라벨 비율을 동일하게 유지 | 클래스 불균형 데이터 처리 (이탈자 vs 잔존자) |
| Time-based Split | 시계열 데이터는 시간 순서대로 분리 | 예: 2023년까지 학습, 2024년은 테스트 |
Test Set은 한 번만 사용해야 함! → 하이퍼파라미터 튜닝에 사용되면 안 됨 (오염 위험)
Validation Set과 Test Set은 역할이 완전히 다름 → Validation: 튜닝용 / Test: 최종평가용
728x90
반응형
LIST